In my last few weeks and months at EMBL-EBI I put a lot of energy and time into improving and embedding team processes and documentation. This broadly fell into four areas:
- Sharing insights from user research studies
- Documenting front-end functionality and specifications
- Embedding and improving Agile processes
- Clear processes for setting up new projects
Sharing user research insights
I carried out several different user research studies during the 8 years I was in the team. Some of these were carried out before current team members had joined the organisation. I was frequently asked questions like “What do we know about how researchers look for data in literature?” or “What do we know about how information specialists construct search queries?”. For each research study I had created an insights report. But these were often buried in project folders within Google Drive. I created a Confluence page which linked to all the outputs such as interview notes, recordings and insights reports. However this didn’t make it easy to find all research on a particular topic or component as insights come from many different studies and other sources.
To help answer these types of questions, especially after I had left the team, I decided to create a user research insights repository in AirTable. I first created a taxonomy for how insights should be organised in Miro. The orange stickies are the categories and the green stickies are the lookup values. Organising and tagging the insights in this way meant they could be filtered by website component or feature, the type of content e.g. preprints, user role and career stage and research study.
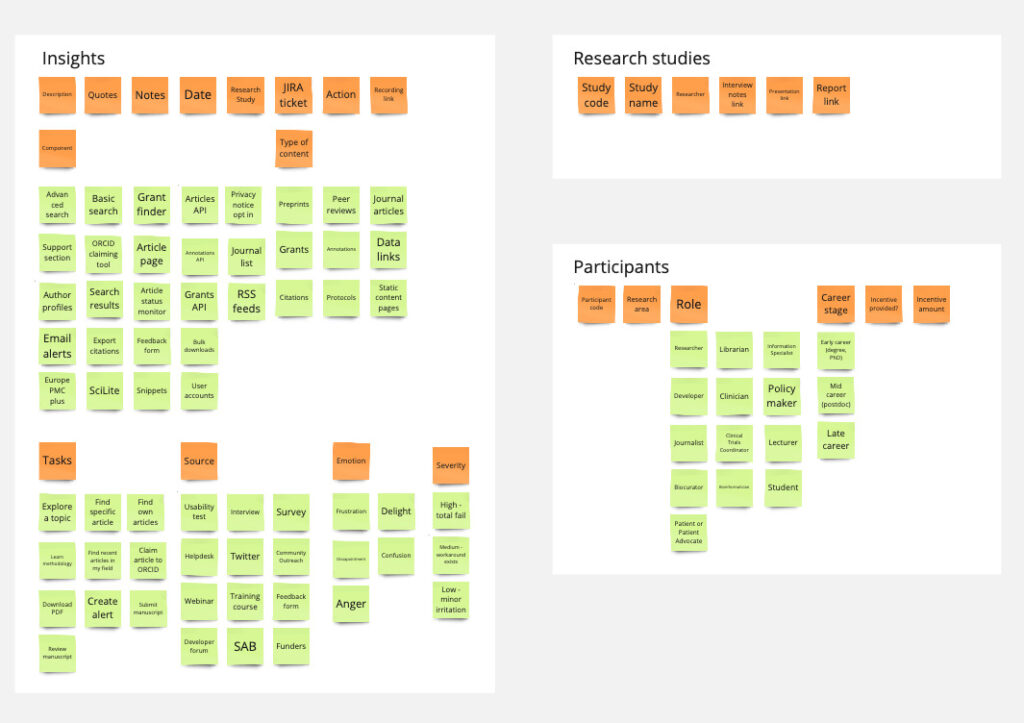
Once I’d done this I created the structure in AirTable and started to populate it with research insights from previous user research studies and other sources of user feedback, including our Helpdesk. When you have an insights repository it’s important to ensure each study and participant has a unique code and these are used to cross reference anonymised notes, recordings and quotes or insights stored in other places. We came up with a simple way of constructing these unique codes as follows:
ADV-MAR-22
[3 letter study abbreviation]-[MMM]-[YYY]
For participants we simply added the participant number to the study code:
ADV-MAR-22-P01
[3 letter study abbreviation]-[MMM]-[YYY]-[Participant_no]
We also kept a master list of all studies and participants which is access controlled for data protection reasons.
When creating the insights repository I was concerned about how much it would get used and whether my effort had been worthwhile. Especially if you won’t be around to see it being used. However, in my last week I was speaking with my Team Leader and she mentioned a research grant proposal she was in the process of writing. It transpired there were some very relevant insights from discovery research in 2018. It was reassuring to know the insights repository already had the potential to become a useful resource.
Front-end Documentation
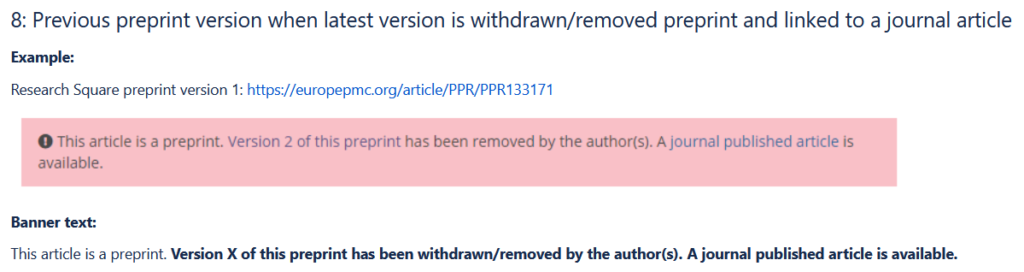
Europe PMC contains over 42.9 million articles, preprints, books and documents. The metadata for each article or document varies considerably. As a designer I’ve learned the importance of designing for a multitude of different scenarios and handling all edge cases in the design. For example there are over 15 different scenarios for displaying notification banners on preprint pages and a hierarchy of logic for which version to use, as per the example below which is used on this preprint page.
We redesigned the front-end of the website in 2018, but there was no existing documentation about how all of the front-end functionality worked. We spent a lot of time reverse engineering how functionality on the front-end worked. Sometimes we missed scenarios and edge cases in our UX designs that we weren’t aware we had to design for. To make this easier in future for the UX Designer, new Front-end Developers and my successor in the Product Manager role I wrote detailed documentation for all our front-end features in Confluence. The screenshot below shows all the documentation for the article page, one of the main page types in Europe PMC.
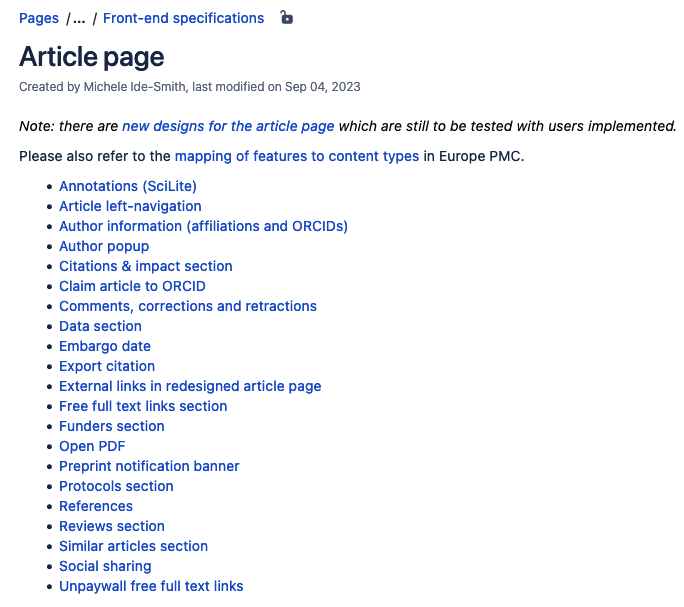
Each feature has a page that includes user stories, acceptance criteria, details of how the functionality works with all possible scenarios and variations of the design, technical details and known issues.
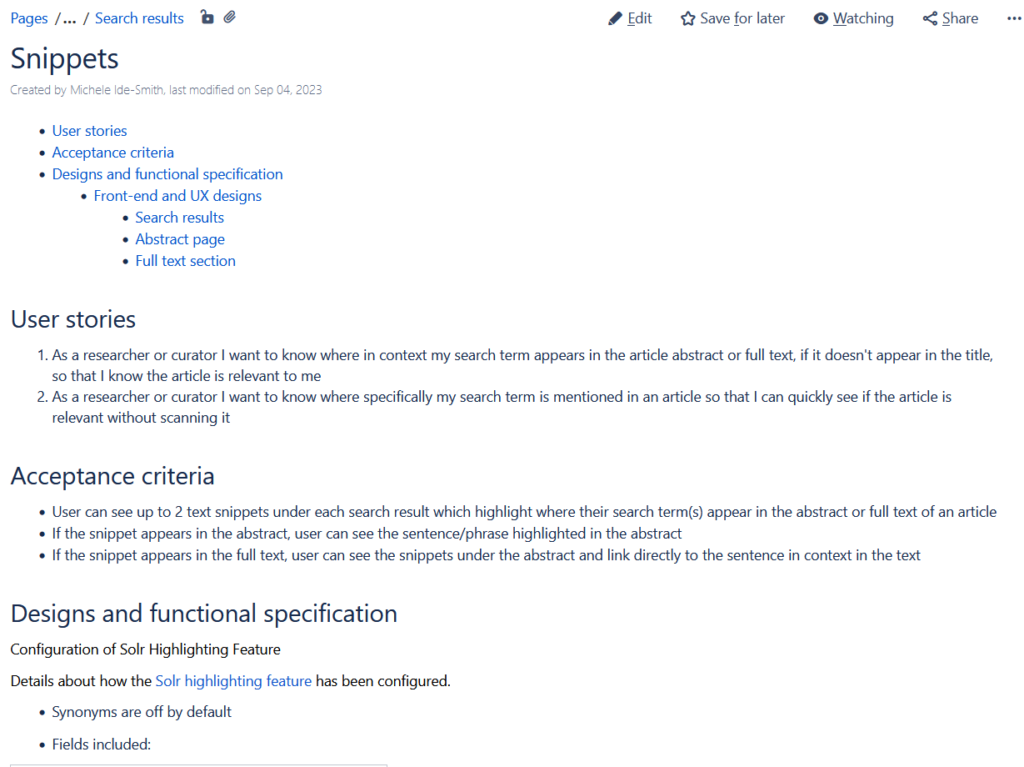
The documentation proved helpful for new starters in the team to provide context about user needs and business requirements. Whenever anyone asked how something worked I would point them towards the documentation first. I also got other people to sense check the documentation and edit and improve it. Good documentation needs to be kept up to date when designs and functionality change. Updating documentation was therefore included in the team’s ‘definition of done’ checklist.

Agile and JIRA processes
We set up an Agile working group to improve our Agile processes. The working group defined some ‘pillars’ to focus on:
- Scope and when to use Agile
- Roles and responsibilities
- Team adoption
- Monitoring and measuring
- Processes
- Estimation system
- Meetings / ceremonies
- Standards, best practice and templates
For each of these pillars we came up with various questions that needed further investigation and decisions and actions for the group.
As well as being part of this group I documented our project processes and spent time tidying up our configuration of JIRA to make it clear when to use Scrum vs. Kanban approaches.
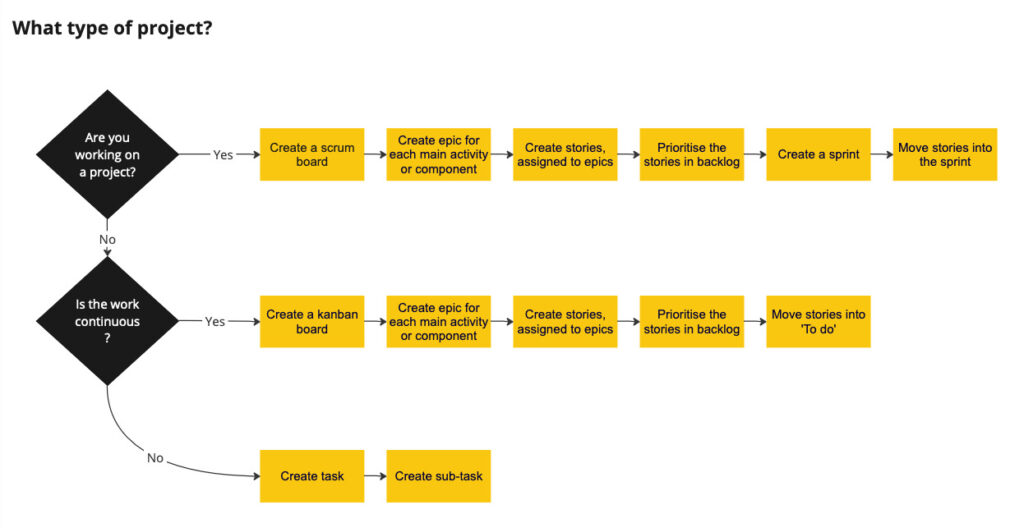
JIRA is highly configurable and can become very messy over time if it’s not managed. The team had been using JIRA to manage work for at last 12 years and I discovered we had almost 30 different statuses for Agile workflows! Many of which were duplicates of each other. Scrum board columns and statuses were being used inconsistently and there was no clear agreement on the workflow. I ran a workshop with the team to reach consensus on the workflow process and statuses we needed. I then tidied up JIRA to streamline the options available and standardise the column layouts of our scrum boards. I wrote guidance for the team on how to use JIRA effectively for managing work.
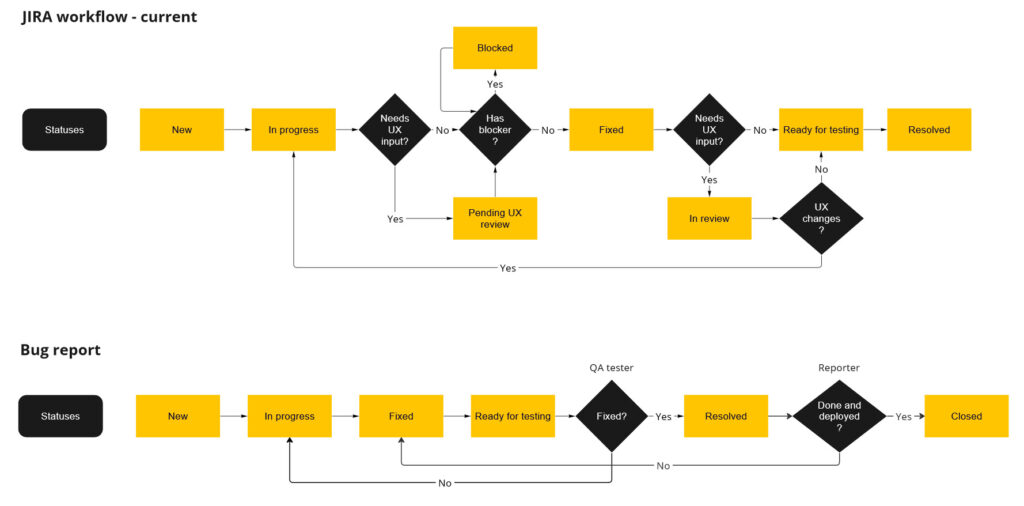

I arranged some Agile training and coaching to help facilitate some discussions in the team about our processes and estimation. The team worked hard on improving their estimating and measuring time spent on different activities with the aim to provide better data to the Team Leader to inform decision making going forward.
Project Canvas
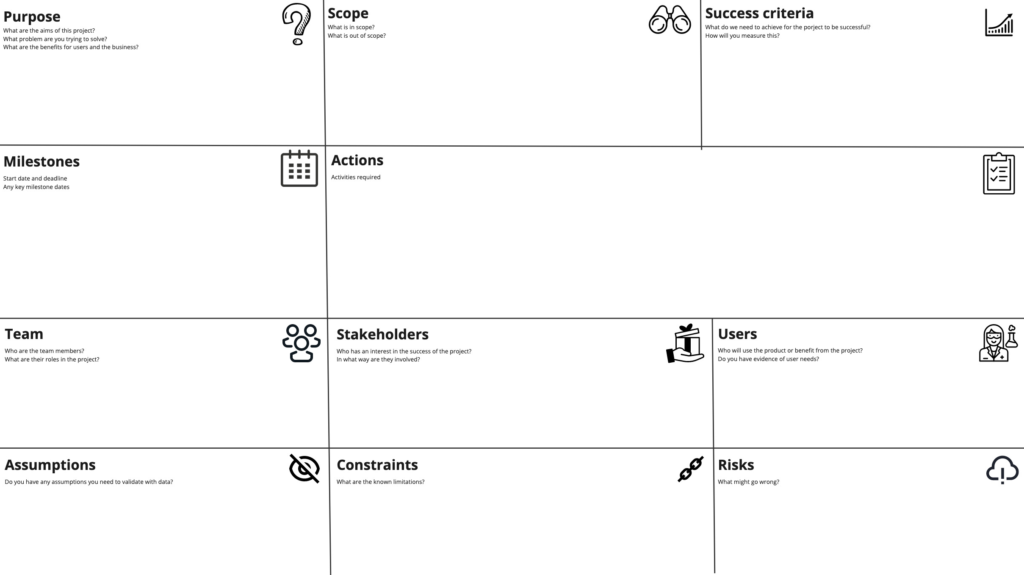
An issue I came across time and time again is that we’d get halfway through a project and discover that the team wasn’t clear why we are doing the project. This was often because a work stream had been defined in our grant objectives a couple of years earlier, but the goals were unclear to the team. I gained a reputation for asking “What problem are we trying to solve?” or “Why are we doing this? What are we trying to achieve?”. Initially I created a Google Doc to help project teams capture the problems we were trying to solve, who the customers and stakeholders are, the scope, success criteria and any assumptions, constraints and risks. I found that product owners felt compelled to create long documents which were time consuming to create and to read. To streamline this activity I created a project canvas in Miro which constrained the amount of text that could be written. The project canvas proved to be very useful and is now used at the project setup stage, to get the team on the same page about what we’re doing, why and who for.
In this series of posts about navigating change I’ve covered:
- Introducing new ways of working
- Influencing stakeholders and strategy
- Leadership during change
- Embedding processes and best practice
These posts represent some of my personal reflections and learnings but I hope that there might be some useful learnings to share with others.
During my time at EMBL-EBI I had a fantastic opportunity to share existing knowledge and skills with my team, as well as learning new skills which I can take with me to my next role. I had the opportunity to collaborate with partner organisations and stakeholders in the US and Europe, and I worked on some very impactful projects. My team at EMBL-EBI were collaborative, friendly and international. I worked with colleagues from Bangladesh, Brazil, China, Cyprus, Czechia, France, Egypt, India, Italy, Germany, Greece, Mauritius, Pakistan, South Africa, South Korea, Ukraine, the UK and the US. I’ll miss them hugely. It has been a privilege and pleasure to work with them and to have contributed to the development of Europe PMC.
References:
Levchenko M, Gou Y, Graef F, et al. Europe PMC in 2017. Nucleic Acids Research. 2018 Jan;46(D1):D1254-D1260. DOI: 10.1093/nar/gkx1005. PMID: 29161421; PMCID: PMC5753258.
Ferguson C, Araújo D, Faulk L, et al. Europe PMC in 2020. Nucleic Acids Research. 2021 Jan;49(D1):D1507-D1514. DOI: 10.1093/nar/gkaa994. PMID: 33180112; PMCID: PMC7778976.