
Key outcomes:
- Over 50,100 machine readable, full text COVID-19 preprints available in Europe PMC, enabling researchers to access to the latest COVID-19 research and data for vaccine and treatment development during the pandemic.
- Scaled XML conversions and QA operations by 2000% in 2 months.
My role:
- Leading a cross-functional team of 10 to design and deliver new infrastructure, processes and outcomes within 2 months.
- Designing author communications and workflows to instill trust.
- Managing the supplier relationship and budget to enable rapid scaling of XML conversion operations.
Scientific research has traditionally undergone a rigorous peer review process by experts in the field, before being published in journals and available to read. Prior to the pandemic, preprints were a relatively new format of research article that enable researchers to share their results and data early, before journal peer review is complete.
At the start of the COVID-19 pandemic, it became clear that immediate access to scientific research and data on the new coronovirus was critical, so that treatments and vaccines could be developed quickly, safely and effectively. The European Bioinformatics Institute (EMBL-EBI) received grant funding from Wellcome, the Swiss National Science Foundation and the Medical Research Council to create a collection of full text COVID-19 preprints in machine-readable, structured XML format to enable deeper analysis.
As the Chief Scientist of WHO I welcome the huge increase in the use of pre-prints by researchers to rapidly share the emerging evidence from the many studies on Covid-19. However, these are published as .pdf documents and I recognise that the information they contain could be more rapidly searched and linkages made between the results and data they contain if they were converted to the standard publishing language XML. I therefore support this initiative by Europe PMC to take on this task.
Dr. Soumya Swaminathan, Chief Scientist, WHO; 4 May 2020
The challenge
The project had three key challenges:
- Building new technical infrastructure and data pipelines to ingest preprint pdf files and store machine readable, structured XML files. And defining criteria to determine which preprint servers to get pdf files from.
- Converting thousands of pdf files to JATS XML per week and quality checking them. At the time of this project, fully automated conversion to high quality XML format was not possible. Some manual processing and checking was needed, especially where mathematical or chemical notations were used.
- Managing the communications with preprint authors and getting their approval to display their preprints on Europe PMC.
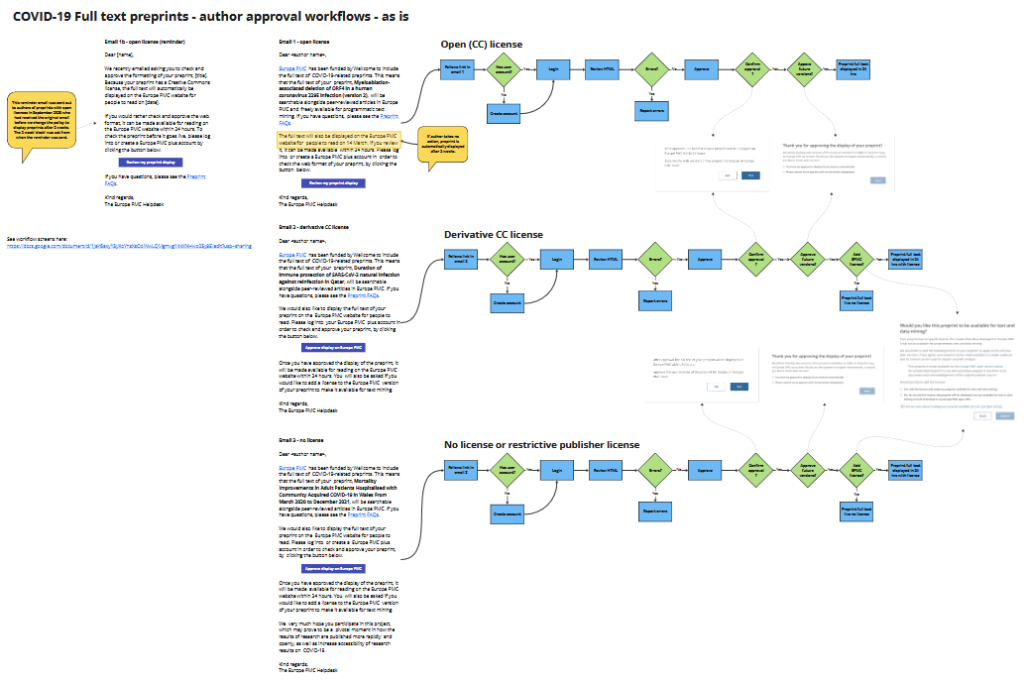
Some life sciences preprints have restrictive licenses which meant they couldn’t automatically be displayed on Europe PMC without the author’s approval. Preprints with CC BY licenses could be displayed. But we decided to give all preprint authors the opportunity to review the conversion of their preprint to XML/HTML and approve the display of the full text on Europe PMC. Many authors had not heard of Europe PMC before, so our initial email communications and approval workflows had to be clear, simple and instill trust.
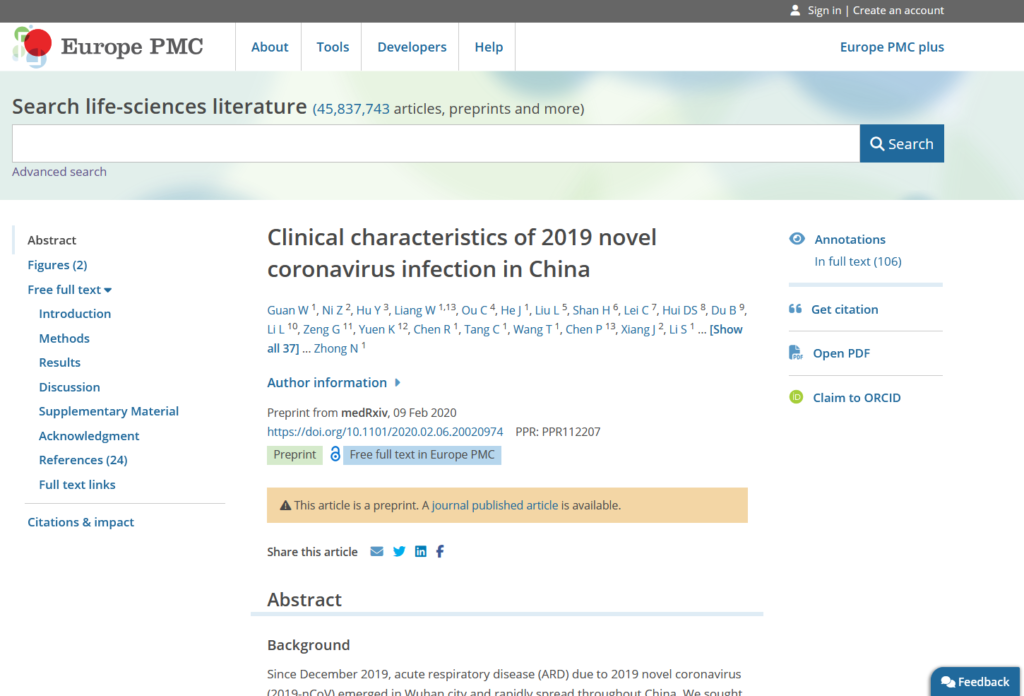
We also wanted to make it easy to find and view preprint articles on Europe PMC, alongside peer reviewed articles. Because preprints are not fully peer reviewed, It was important for readers to be able to clearly distinguish preprint articles from peer reviewed journal article content and make their own decisions about the robustness of the science.
Vision and strategy
I worked with the Associate Director of the Institute and a Data Scientist to write a grant application and define the vision and strategy for the project.
Delivery
Once the grant had been awarded, I planned and led the project delivery with a team of 10 people (developers, QA, data science, UX, Helpdesk).
Metadata and PDF files were ingested from preprint servers based on a set of criteria and a consistent COVID-19 search query. The technical team tackled one preprint server at a time, starting with the ones that had the most COVID-19 preprints. Where possible Crossref metadata was used.
We chose to adapt our existing manuscript submission system based on the open source framework PubSweet for managing author approval workflows. I created flow diagrams (see below) to ensure the team were aligned on the workflow steps and email text. I worked with the UX Designer, Developer and Helpdesk to design email text and screens in the author workflow preprint pages and test them with users.
I worked closely with our vendor in India, our Data Scientist and internal Helpdesk team to scale the XML conversion and QA operations by 2000% within 2 months. Using a spreadsheet predicting the number of COVID-19 preprints expected per week, we were able to plan resource allocation and ramp-up effectively, using daily calls to check-in and adapt our plans as needed.
The UX designer and I collaborated on design changes to the search results interface and preprint page display to ensure readers were clear they were looking at an article that had not been peer-reviewed.
Metrics tracked included author approval rates by license type and conversion progress.
Launch
As a team we gathered and responded to live service data and feedback from users via the Helpdesk and Twitter.
After launch I worked closely with the Data Scientist to analyse live service data, for example the number of preprint approvals by license type.
I managed the project budget and created a forecasting spreadsheet so that we could predict how long the funding would last. I also produced reports for the funders.
Outcomes
Over 50,100 full text COVID-19 preprints were indexed in Europe PMC, providing researchers and clinicians with access to the latest COVID-19 research and data. The collection has been used in systematic reviews and meta analysis studies. As a team we defined best practice standards and shared these with the open science community.
Learnings
There was limited time for user research due to the urgency of the pandemic situation. With more time I would have done more testing with users of the author workflows and emails.
We had mixed feedback from authors – mostly positive but some negative. In part this was because authors were not always aware that they had given consent to journals for their article to be made available as a preprint. And they were concerned that their chances of getting accepted for publication might be affected if the article was available freely on elsewhere.
References
Levchenko M, Parkin M, McEntyre J, Harrison M. Enabling preprint discovery, evaluation, and analysis with Europe PMC. Plos one. 2024 ;19(9):e0303005. DOI: 10.1371/journal.pone.0303005. PMID: 39325770; PMCID: PMC11426508.
Ferguson C, Araújo D, Faulk L, et al. Europe PMC in 2020. Nucleic Acids Research. 2021 Jan;49(D1):D1507-D1514. DOI: 10.1093/nar/gkaa994. PMID: 33180112; PMCID: PMC7778976.
Europe PMC Team. Over 15,300 full text COVID-19 now available in Europe PMC. 2021 Feb.