Category: Work
-
Preprint peer reviews

Preprints are articles that have not passed formal peer review or been published in a journal. Europe PMC started indexing preprint articles in 2018, alongside peer-reviewed journal articles. During the COVID-19 pandemic preprints became increasingly popular as they offered immediate access to research findings and data. But it was left up to the reader to…
-
Article status monitoring tool

Research articles can change status once they have been published, for example they might be withdrawn, retracted or removed. Knowing the status of an article is important for anyone who is citing an article. If an article is retracted, withdrawn or removed it may be due to concerns about the scientific method or results which…
-
COVID-19 full text preprints

Key outcomes: My role: Scientific research has traditionally undergone a rigorous peer review process by experts in the field, before being published in journals and available to read. Prior to the pandemic, preprints were a relatively new format of research article that enable researchers to share their results and data early, before journal peer review…
-
Event organising 2011 – 2020

For 9 years I co-organised a number of community design events and conferences, including the Cambridge Usability Group, UX Unconference and Biocuration 2019. I was the Programme Co-Chair for UX Cambridge, UX Scotland, Service Design in Government conferences, organised by Software Acumen. Cambridge Usability Group The Cambridge Usability Group was a local meetup group for…
-
Europe PMC redesign

Europe PMC is an open access archive of 46.5M scientific articles, that supports the open access policies of 37 funders. The primary users are life sciences researchers (academic and industry), clinicians and biocurators. The challenge When I joined the team they had limited knowledge of user-centred design, no user research insights or behavioural analytics and…
-
Funder impact dashboards
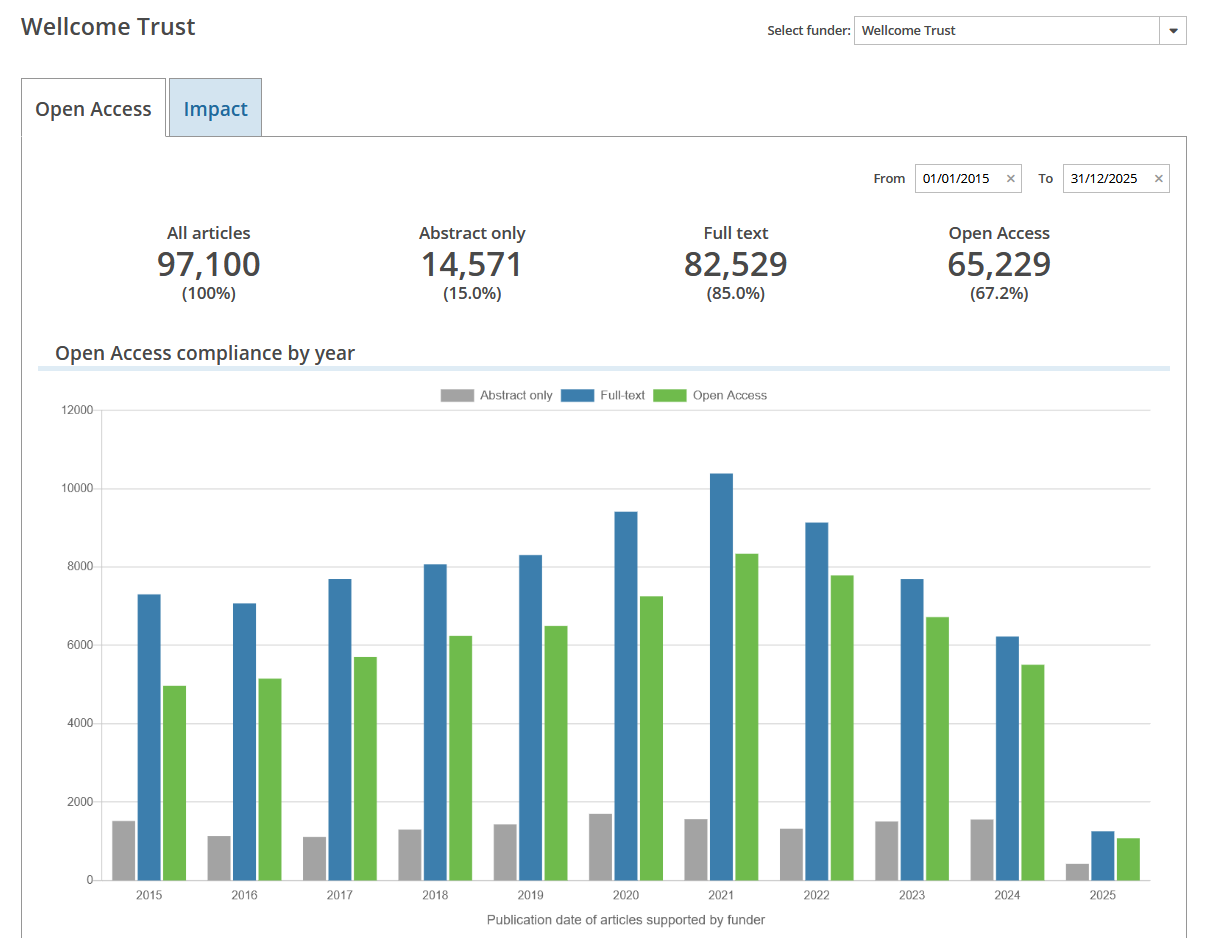
Europe PMC is funded by 35 biomedical funders and charities. Researchers who receive grant funding from these organisations are required to publish any articles resulting from the research open access, and ensure that the full text of the article is available in Europe PMC in a machine readable format. Funders need to keep track of…
-
Annotations
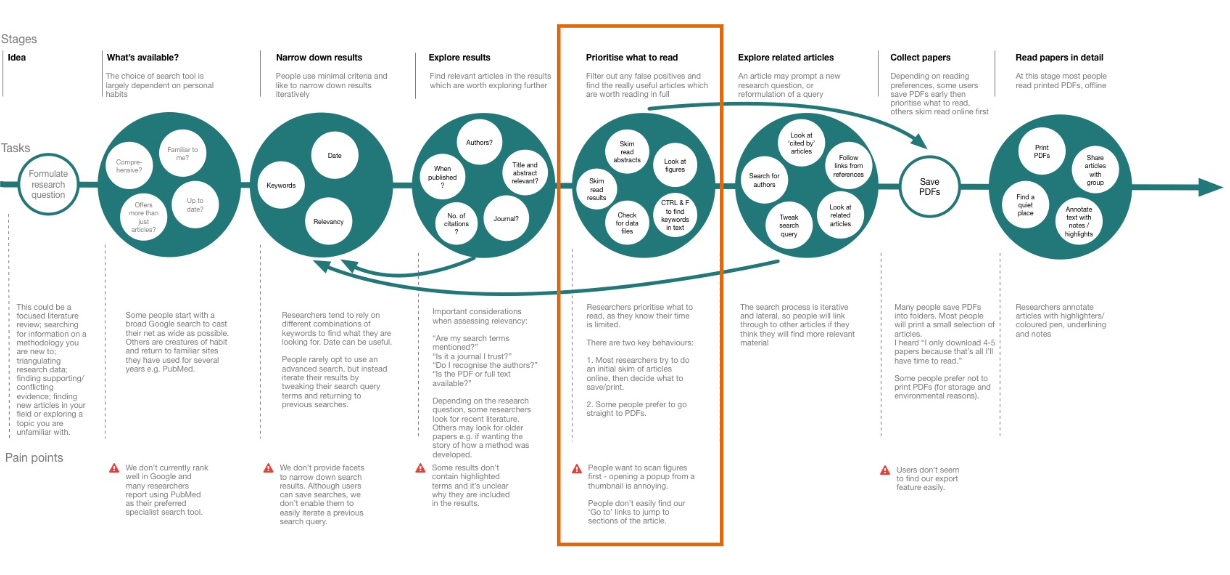
There is a wealth of information in scientific articles. Europe PMC contains millions of life sciences articles. Finding specific evidence within such a huge corpus of research literature has historically been very challenging for researchers and biocurators. When I joined the Europe PMC team they had already put in place text mining algorithms to automate…
-
Author profiles

Europe PMC provides access to millions of life sciences research articles. It can be challenging to find articles by a particular author or co-author, particularly if they have a common name. To resolve this issue, Europe PMC integrates with ORCID, the registry of unique, persistent identifiers for academic researchers. Authors can maintain their own ORCID…

